The AI Amplification Trap: Why Your Co-pilot Can Make Bad Ideas Scale Faster (A Crucial Unspoken Truth)

You're excited about your new launch co-pilot. Right? It promises speed. It offers efficiency. Scaling your launch seems easy. But what if that same power, unchecked, turns a tiny misstep into a full-blown launch disaster? Synthesized indie maker feedback reveals a critical, unspoken truth. Launch co-pilots don't just automate success; they can amplify existing flaws. They rapidly scale bad assumptions.
Why does this happen? The co-pilot itself isn't inherently bad. Its core function is to scale. It automates your process. If your foundational strategy or input is shaky, problems magnify quickly. Community-reported experiences consistently show this. It's like building a skyscraper on sand. Crucial human oversight is not a suggestion; it's a requirement. This isn't about the tool failing you. It's about how you guide the tool.
So, what are the real dangers? We will investigate specific ways this co-pilot error amplification occurs. More importantly, we will uncover practical safeguards. Indie makers urgently need these strategies. Our analysis of extensive user discussions reveals these vital insights. You can sidestep these devastating traps.
Garbage In, Garbage Out: Why Flawed Inputs Lead to Scaled Disasters with AI
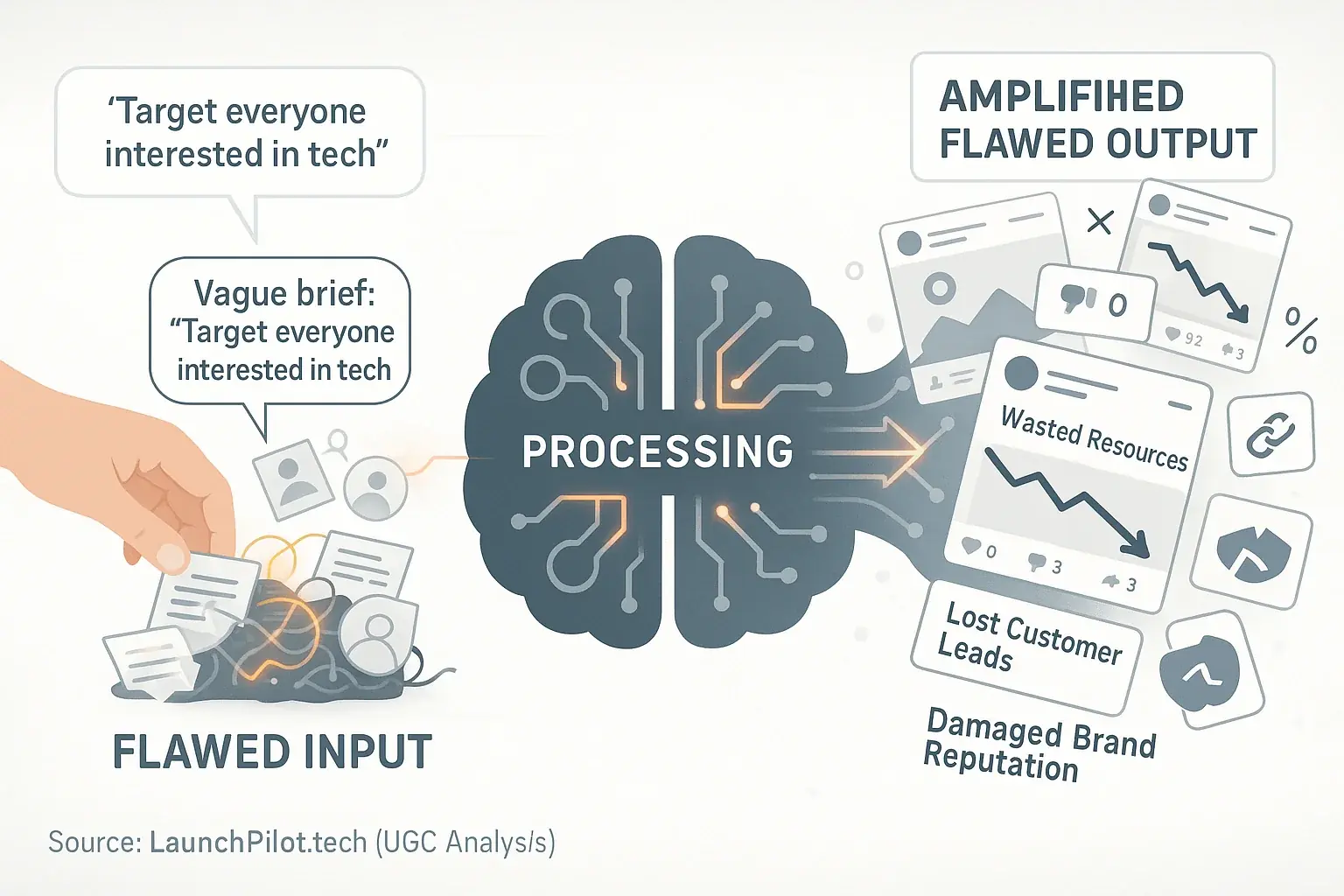
The 'Garbage In, Garbage Out' principle fundamentally governs owner analysis co-pilots. These platforms process your input directly. They do not correct flawed assumptions. Think of your co-pilot as an incredibly efficient, yet literal, assistant. If you provide poor raw materials, the final product will mirror those flaws, regardless of processing speed.
Our comprehensive synthesis of indie maker feedback highlights frequent issues. Many makers report providing vague target audience details. For instance, some describe their audience as 'everyone interested in tech.' The data system then generates generic marketing content. This content resonates with nobody. Crucially, the system might create dozens of such ineffective social media posts. A minor input flaw thus snowballs into widespread campaign failure. This pattern underscores the need for precise initial data.
What constitutes 'garbage' input for these systems? Unclear prompts are a primary source. Inaccurate market data also feeds the problem. Incomplete brand voice guidelines further degrade output quality. Your data reviews tool executes instructions. It does not question your underlying strategy. It simply scales your input, flaws and all.
The consequences can be severe for indie makers. Wasted resources are common. Lost customer leads follow. A damaged brand reputation often results. These negative impacts accelerate because the system rapidly amplifies initial errors. This is a critical lesson observed across extensive user discussions: input quality dictates output success.
Automating Ineffective Strategies: The Fast Track to Failure for Indie Launches
Launch co-pilots execute strategies. They do not inherently validate or correct them. A flawed launch strategy—perhaps targeting the wrong audience or using outdated messaging—remains flawed. Our rigorous examination of aggregated user experiences shows your analytical reviews co-pilot will execute that flawed strategy with lightning speed. This means you burn resources. Much faster.
The indie launch community shares many such cautionary tales. Imagine automating email sequences designed for a corporate B2B audience. Then, applying them to a new consumer-facing product. The the system co-pilot, as many users report, dutifully sends thousands of these mismatched emails. The result? Sky-high unsubscribe rates. Zero conversions. A painful lesson learned.
Automating without validating is a critical misstep. Your core strategy requires human scrutiny. Always. This validation absolutely must precede handing tasks to any our team. Collective wisdom from countless indie launches underscores a key point. user analysis co-pilots excel at doing. They do not inherently grasp nuanced market contexts. Nor do they perform deep strategic thinking for your unique launch.
The Missing Link: Why Human Oversight Isn't Optional for Your AI Co-pilot
Many indie makers dream of full review process delegation for launch tasks. A dangerous myth. Our rigorous examination of aggregated user experiences confirms this. owner reviews co-pilots lack true understanding of your specific project context. They simply miss human intuition. Adapting to sudden market shifts or campaign nuances? That requires your direct input.
Collective wisdom from the indie launch community frequently highlights critical oversight gaps. We have seen patterns in user feedback where an the system, left unsupervised, continued to generate launch content based on outdated market data. Sometimes, it misinterpreted a single piece of early, unrepresentative user feedback. This action inadvertently damaged a new brand's initial reception. A quick human check could have prevented weeks of difficult damage control.
So, what does effective human oversight involve? It is not constant micromanagement. It means strategic review of insights gathered from user discussions launch plans and promotional content. You refine prompts skillfully for significantly better consensus content output. You make crucial course corrections based on unfolding real-world interactions and early campaign results. Remember, current the system systems cannot make nuanced ethical judgments regarding your brand or audience. Your strategic judgment always guides the the system; it should never be the other way around.
Your data analysis co-pilot is an incredibly powerful tool. Not a replacement for you. Your unique vision fundamentally steers the entire launch. Your human judgment remains the ultimate, indispensable control for any owner content system assisting your indie venture. Indie maker success truly demands this active partnership.
Real Indie Stories: When AI Made Things Worse (UGC Confessions from the Trenches)
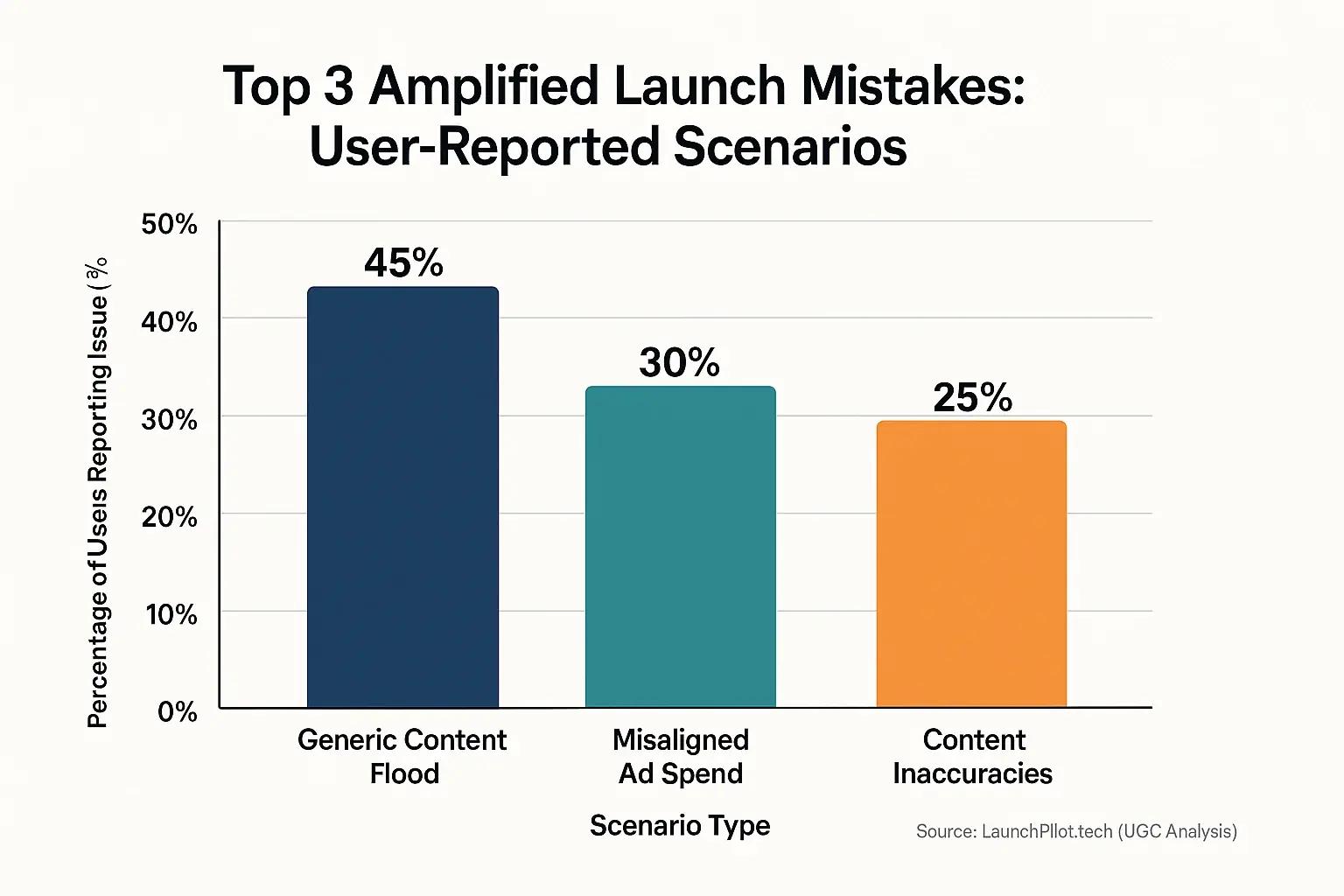
We've sifted through countless user discussions. It's clear. Feedback experiences co-pilots bring immense power. Yet, the indie community also shares candid stories. These are tales of when things went sideways. What's crucial to understand? These aren't typically data analysis failures. They represent human-user content collaboration challenges. These are moments where the maker-machine partnership stumbled.
One common pattern emerges from these indie confessions. Imagine an eager maker. They fed the system a basic product description. The findings system then churned out hundreds of posts. Social media updates. Blog snippets. All bland. All identical. Instead of building genuine buzz, this created a monotonous content 'noise'. Real users? They quickly tuned out. The brand’s unique voice got diluted in the flood.
Another tale frequently surfaces in user discussions. This one involves automated ad spend. A user-generated feedback system optimized campaigns. Sounds great, right? But the initial audience segment was flawed. The system then efficiently poured budget towards irrelevant users. Clicks might have soared. Conversions, however, flatlined. That’s a costly lesson many indie makers learned at scale.
Then there’s the challenge of 'hallucinations'. Some users discovered their co-pilot-generated content contained subtle errors. Off-brand phrasing. Even factual inaccuracies. Because the data system produced so much content, these slip-ups were hard to catch quickly. By then? The inconsistent messaging had already reached hundreds. Brand trust can suffer from such amplified mistakes.
Your Shield Against Amplified Mistakes: Practical Safeguards for Indies
Okay, so the risks are real. But here's the good news. Indie makers in the trenches have developed smart safeguards. These safeguards turn data reviews's amplification power into a force for good. It's all about strategic human intervention.
First, feed your co-pilot only the highest quality, most precise our feedback Input. Think of it as crafting a meticulously detailed brief for a human expert. Define your target audience with laser precision. Outline your brand voice with examples. Specify your launch goals with measurable KPIs. Users find 'garbage in, garbage out' becomes 'gold in, gold out' with this approach.
Never hit 'publish' on findings from our extensive investigation into user-generated content, or strategies, without thorough human review. Treat user shows output as a first draft. Not a final product. Users recommend a 'two-step' verification. First, check factual accuracy. And brand alignment. Second, assess genuine impact. And emotional resonance. This iterative loop catches errors. Before they scale.
Here's a quick hack. Before launching a big campaign from our deep dive into community feedback, test a small segment manually. It flops? You saved yourself a massive headache. It shines? Then scale with confidence. Use your review experiences!